Bangla Word Frequency
I was curious which Bangla words come up most frequently, so I wrote a program to analyze articles from the Anandabazar Patrika newspaper. The current results come from the articles from all of 2012. One of the things that came up right away is that in Bangla words get modified in various ways. The word বই might appear as বইটি. A verb like করা may show up in conjugated form as করেছেন. I thought it would be a lot more informative if these words were counted as one word for the purpose of determining frequency. So my program tries to figure out whether a word is a modified form of some other "base" word.
Here is a screenshot of the word frequency list:
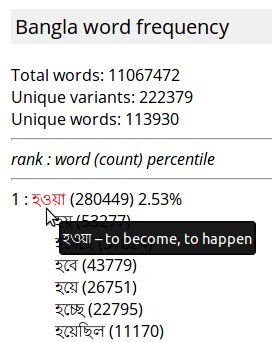
At the top, "Total words" counts how many instances of words it scooped up from the articles. If a word like হয়ে appears 26751 times then it gets counted that many times. Below that are the "Unique Variants", wherein those 26751 instances of হয়ে are only counted once. Below that, "Unique words" is computed by consolidating variants like হওয়া, হয়ে and হবে into a single category and counting them all as a single unique word, in this case হওয়া.
Below those three counts is a header that shows how the entries are formatted below that. The rank just indexes the words in order of their frequency. The word হওয়া is ranked number one because no other word was counted more than 280449 times. The percentile indicates what percentage of the words seen were হওয়া and its variants, plus the words that came before it in the ranking. Thus the percentile continually increases until it gets to 100% at the end of the list. Indented beneath each main entry are all of the variants that were found, sorted in order of decreasing frequency, along with the count for each.
Notice the word হওয়া is highlighted and since the mouse is hovering over it the definition "to become, to happen" is being displayed. Try hovering your mouse over this হওয়া and see if it works for you. You may have to hold the mouse still for a second or two.
I've truncated the (rather huge) list according to several criteria below, with each list longer than the one before it:
- Words used at least once per day
- Words needed for 90% of the newspaper
- Words needed for 95% of the newspaper
- Words used more than once in a year
- All words used in a year
- Bonus: words used more than once in Satyajit Ray's short story collection Galpo 101
- Bonus: words used more than once in movie subtitles, based on this data, used under this licence.
A few notes about the system:
- Each word and variant has a space before and after it. This can help you search for words with a given prefix or suffix using your browser's Find feature. For example, if you wanted to find all of the causative verbs you could search for "নো " (note the space after it). You'll still get some words that are not causative verbs because other words also end in নো, but you'll get far fewer than if you just searched for "নো".
- The system doesn't know what to do about ambiguities. For example, থেকে has its own definition in the dictionary, so it shows up as a base word, not as a variant of থাকা, although that would also be a reasonable way to count it.
- The system makes mistakes if a word is not in the dictionary but is a plausible variant of some other word, even though it's really not. As I find these words and add their definitions these errors will diminish.